State Space Models for Poll Prediction
Posted onMotivating Example
I have always been interested in state space modeling. It is really interesting to see how this modeling strategy works in the realm of opinion polling. Luckily I stumbled across an example that James Savage put together for a workshop series on Econometrics in Stan. Additionally, while I was writing this blog post by happenstance Peter Ellis put out a similar state space Bayesian model for the most recent Australian elections. His forecasts were by far the most accurate out there and predicted the actual results. I wanted to borrow and extend from his work as well.
Collect the Data
This is the original data collection routine from James Savage’s work.
# The polling data
realclearpolitics_all <-
# Scrape the data
polls <- realclearpolitics_all %>%
%>%
%>%
Develop a helper function.
# Function to convert string dates to actual dates
{
last_year <- >0
dates <-
dates <-
first_date <- %>% unlist
second_date <- %>% unlist
}
Continue cleaning.
# Convert dates to dates, impute MoE for missing polls with average of non-missing,
# and convert MoE to standard deviation (assuming MoE is the full 95% one sided interval length??)
polls <- polls %>%
%>%
%>%
%>%
%>%
# Stretch out to get missing values for days with no polls
polls3 <- %>%
%>%
%>%
I wanted to extend the data frame with blank values out until closer to the election. This is that step.
polls4 <- polls3 %>%
# One row for each day, one column for each poll on that day, -9 for missing values
Y_clinton <- polls4 %>% reshape2:: %>%
dplyr:: %>%
as.data.frame %>% as.matrix
Y_clinton <- -9
Y_trump <- polls4 %>% reshape2:: %>%
dplyr:: %>%
as.data.frame %>% as.matrix
Y_trump <- -9
# Do the same for margin of errors for those polls
sigma <- polls4 %>% reshape2::%>%
dplyr::%>%
as.data.frame %>% as.matrix
sigma <- -9
Our Model
I have modified the model slightly to add the polling inflator that Peter Ellis uses in order to account for error outside of traditional polling error. There is a great deal of literature about this point in the Total Survey Error framework. Basically adding this inflator allows for additional uncertainty to be put into the model.
// From James Savage at https://github.com/khakieconomics/stanecon_short_course/blob/80263f84ebe95be3247e591515ea1ead84f26e3f/03-fun_time_series_models.Rmd
//and modification inspired by Peter Ellis at https://github.com/ellisp/ozfedelect/blob/master/model-2pp/model-2pp.R
// saved as models/state_space_polls.stan
data {
int polls; // number of polls
int T; // number of days
matrix[T, polls] Y; // polls
matrix[T, polls] sigma; // polls standard deviations
real inflator; // amount by which to multiply the standard error of polls
real initial_prior;
real random_walk_sd;
real mu_sigma;
}
parameters {
vector[T] mu; // the mean of the polls
real<lower = 0> tau; // the standard deviation of the random effects
matrix[T, polls] shrunken_polls;
}
model {
// prior on initial difference
mu[1] ~ normal(initial_prior, mu_sigma);
tau ~ student_t(4, 0, 5);
// state model
for(t in 2:T) {
mu[t] ~ normal(mu[t-1], random_walk_sd);
}
// measurement model
for(t in 1:T) {
for(p in 1:polls) {
if(Y[t, p] != -9) {
Y[t,p]~ normal(shrunken_polls[t, p], sigma[t,p] * inflator);
shrunken_polls[t, p] ~ normal(mu[t], tau);
} else {
shrunken_polls[t, p] ~ normal(0, 1);
}
}
}
}
Compile The Model
state_space_model <-
Prep the Data
clinton_data <-
trump_data <-
Run the Model
clinton_model <-
trump_model <-
Inferences
# Pull the state vectors
mu_clinton <- %>%
as.data.frame
mu_trump <- %>%
as.data.frame
# Rename to get dates
<-
<-
# summarise uncertainty for each date
mu_ts_clinton <- mu_clinton %>% reshape2:: %>%
%>%
%>%
mu_ts_trump <- mu_trump %>% reshape2:: %>%
%>%
%>%
Which gives us the following:
actual_voteshare <-
%>%
+
+
+
+
+
+
+
+
+
+
+
+
+
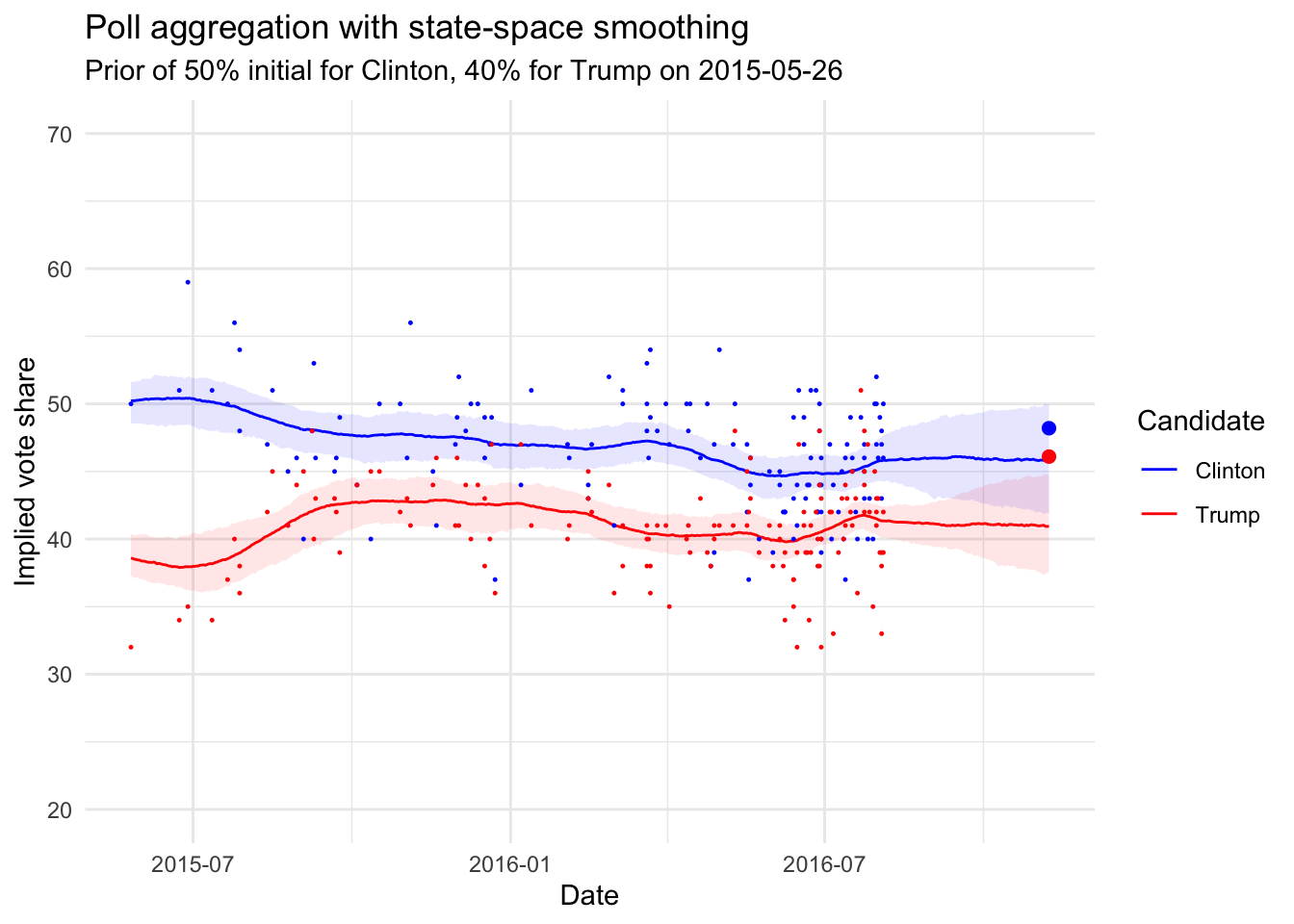
So the outcome was not totally out of the bounds of a good predictive model!
Citation
BibTex citation:
@online{dewitt2019
author = {Michael E. DeWitt},
title = {State Space Models for Poll Prediction},
date = 2019-05-19,
url = {https://michaeldewittjr.com/articles/2019-05-18-state-space-models-for-poll-prediction},
langid = {en}
}
For attribution, please cite this work as:
Michael E. DeWitt. 2019. "State Space Models for Poll Prediction." May 19, 2019. https://michaeldewittjr.com/articles/2019-05-18-state-space-models-for-poll-prediction