Testing Julia Weave with the Rust Blog
Posted on from Winston-Salem, NCTesting Julia
First we can load some julia packages:
First we can load some julia packages:
Will this work?
My first motivation in my work is to do good, meaningful science. Good science means appropriate statistics, reproducible workflows, with as open data as possible.
My secondary motivation is to never have my work torn apart on Andrew Gelman’s Blog, TWIV, or DataMethods. Of course discussion of published literature and the limitations are great. It needs to be done, but I want my work to be the best possible version of itself.
Happy New Year! I hope to be engaged a little more in blogging this year, especially as Twitter seems to be imploding. Someone once told me it is good luck to do a few of things you want to do on New Year Day in order to set the tone for a sucessful day. This normally means reading, writing, thinking, and spending time with family. So I’ll try to start this process right.
Merry Christmas, readers! For those who celebrate, I hope you have a great day of family and fellowship, if that is your thing. If you don’t, I hope that you, too, have a great day of family and fellowship.
The insane number of COVID-19 cases in China is absolutely staggering and my heart goes out to them. To think of a million cases a day is unfathomable. Further, the risk it poses to the world to let a virus run rampant in a population is frightening.
Regardless, I need to get back into writing here more frequently.
The other day I finished watching the National Geographic series titled “Hot Zone” based on the book by Richard Preston. The whole story is centered primarily on the Reston Virus, an Ebolavirus from the same genus as the Zaire and Sudan Ebola viruses which have ravaged human. Unlike those other viruses, Reston Virus does not appear to be pathogenic to human, but is very much so to non-human primates. This is despite not being that dissimilar, which is cause for concern.
@seabbs started a very thought provoking thread on mastodon the other day. It only came to my attention today (because I haven’t yet figured out the whole timeline thing). The entire contents of the post are located here in which he asks what should the role of academics be in designing public health surveillance and outbreak response systems. He asks all the right question along the line of are academics (including PhD students, post-docs, early career researchers, etc) the right people to be designing these systems and/or the tools to respond to them. Are the incentives and expertise aligned (e.g., who funds whom and how are careers made). It is a real problem and an open question for public health and academic on how to organize on this topic. It is further compounded by the fact that there are other partners in this dance. There are normal funding government mechanisms, extra/intra-mural funders, NGOs (e.g., like Wellcome, Gates, GAVI, CEPI, among others) and the brass tacks of promotion, compensation, and ego.
I was listening to the learning Bayesian statistics podcast in which the host interview Justin Bois of Cal Tech. When listening to how Justin came into statistics from chemical engineering (a story similar to my own), I was struck with how natural the transition from engineering is to Bayes…. My first serious introduction to applied statistics was through projects designed to identify process variation. The experienced engineers all taught me that variation is natural, something you want to reduce in manufacturing, but never something that could be eliminated. That comfort with not having a fixed number led to higher comfort with probabilistic reasoning.
More to write on this later.
So Elon bought Twitter. I have always been a bit ambivalent about using platforms in which I am the product. In some cases the ends justify the means, but someone who outwardly endorses things I am vehemently against is something of which I will not put. I’m going to spend more time blogging, coding, and tooting1 at @medewitt@mastodon.social.
yeah I know that will take some getting used to. ↩
Not too much to say on this topic other than I think that is is my new favorite tool.
Modules allow you to better encapsulate code by placing subdirectories in their own repository. These can then be added using the :
git submodule add URL
Then you can be off to the races. This also solves some of the problems with trying to deploy websites at a subdomain using a third party service
A long time ago now someone I deeply respect told me I ought to learn some PHP.
I didn’t.
However, this website rendering engine is in pretty simple (but simple doesn’t mean unelegant) PHP code. The way the initial code is written, if a given post has a non-date name (e.g., YYYY-MM-DD-something.md) the current code would strip the file extension but leave the remaining letters. When PHP tries to convert these to a date it fails and returns the begining of PHP time (Jan 1, 1970). I ended up fixing the code for my use by just substring the first ten characters and all is well. However, that’s the point of this post. Once you have fluency in one or more programming language, especially general purpose ones, you can move in different waters. You at least have an idea of what the idiom is and what to look for and often that makes all of the difference.
This looks really neat! Seems like tikz really is the language of the realm when you need to make these kind of diagrams:
https://tex.stackexchange.com/questions/145269/drawing-blobs
There are some really nice packages in R that need Julia ports. I really have been enjoying using Julia but it reminds me of Base R when I first started using it (e.g., pre-tidyverse). The easystats suite looks really nice and ripe for a port:
I have to say that justfile might be my new favourite multi-lingual build tool. They allow you to use multiple languages within instructions, variables, are less sensitive to tabs, and have some really nice documentation.
This post is exploring the use of Julia, Turing, and ODEs and largely expands on the work from Simon Frost’s awesome epirecipes.
The EPA recently issued updated guidance on acceptable levels of two so-called forever chemicals in the drinking water Perfluorooctanoic acid (PFOA) and perfluorinated alkylated substances (PFAS). These substances are used in non-stick applications and have become pervasive in every day life. Unfortunately, these substances are extraordinarily stable and don’t easy degrade in nature, are not captured by waste-water processing, and have been found for years in human serum. The EPA has been slowly lowering the acceptable levels in drinking water as the science evolves. As is the case with many long-term environment studies it takes a long time to gather observational data (with unknown effect sizes), but unsurprising to anyone they have found that even a little of these chemicals could have negative effects on human health.
tl;dr; porting to Quarto was not terrible. Also moving from GitHub pages to Netlify at the same time was a bit much.
As the parent to a child under the age of five, I have been anxiously awaiting news regarding the availability of a vaccine against COVID-19 for some time. The news recently was that the FDA was encouraging Pfizer/BioNTech to submit the data for their clinical trials for their vaccine candidate for the 6 month to five year old group. Early reporting was that the vaccine wasn’t meeting it’s endpoints with two doses (which were reduced in concentration from the older groups for fear of vaccine induced myocarditis) and would need to pursue a third dose.
NCDHHS has been participating in waste-water surveillance for SARS-CoV-2. Unfortunately, there is some delay in the data (posted weekly and what is posted is generally a week old or more).
The Centers for Disease Control and Prevention updated their COVID-19 guidelines for isolation and quarantine^[Remember, isolate if you are positive, quarantine if you are a contact.] on December 27, 2021 and received some strong backlash. The updates were certainly needed as the prior guidelines were last updated in December 2020 or so when a vaccine was not available and there were many additional unknowns. In the meantime the United States is in the midst of a Delta wave of infections and growing presence of the Omicron variant, the latter appearing to be more fit and better at escaping vaccine or infection derived immunity. This means that many people are in quarantine and isolation at all levels which is causing issues to basic services (e.g., hospitals down critical staff, flights canceled due to crews in quarantine/isolation, day care centers, schools, other commerce activities, end even college football bowl games). While generally there is agreement that the guidelines needed to be updated based on availability of vaccines and boosters, there is some disagreement on the language and the lack of a testing component.
Paxlovid is a new antiviral (protease inhibitor) that when paired with ritonavir provides excellent protection against hospitalization for those patients infected with SARS-CoV-2. Pfizer, the manufacturer, had two endpoints. The first endpoint was for “High Risk” patients and a secondary endpoint for “Standard Risk” patients. I thought it was neat that BioNTech/Pfizer used a Bayesian analysis for their BNT162b2 vaccine and was a little surprised when I saw a frequentist p-value for their second endpoint:
A colleague sent me the following table from a report from the UK REACT Survey:

A prominant scientist has been posting his highlights of pre-prints on twitter during the course of the pandemic and occasionally, I come across one that makes me scratch my head. I think that the move to open and rapid science through pre-prints has been good, but not without issues. Review (and open review especially) makes work better and is an important part of science and progress.
I have been re-reading Anderson and May. Each time I come back to the book I find gems that are highly salient to what’s going on the world today. The gems that I read yesterday was about viral evolution and virulence. The question was about pathogens becoming more virulent over time vs less virulent and this role in transmission. They set it out in the following familiar equation for the basic reproduction number:
}
}
In the R programming environment, you have access to configuration
files, typically your .Rprofile and your .Renviron. RStudio has a
more thorough write-up available at this
link.
On the start of a new R session your Environment file is available
through a Sys.getenv call. Rprofiles are basically “sourced” in the
active R session on start and everything in the Rprofile is available
within the session. Generally speaking, your environment file is for
definitions (like a typical dotfile) which variables given values in the
form of:
My wife and I love to watch the Great British Bake Off on Netflix. The competition is for the most part collegial in general and all around feel good television, especially at night. After watching several seasons of the show, a lingering question came to mind: how good are the judges at estimating talent?
I read Jeremy Farrar’s Spike over the weekend. I don’t have anything insightful to say about it. On this side of the pond, the United Kingdom seemed like it had the best shot of handling this pandemic. The way that scientists and scientific advisors are brought to consult and model in a (from the outside) organized fashion as part of the decision-making process plus the venerable National Public Health Service, they had all the pieces to take informed decisions. In the States, sure we have several regulatory bodies and public health agencies, and a group of rag-tag academic that seem to just publish and post on twitter. Nothing coordinated. Additionally, our health systems are disparate, some state-run, some private, some for profit, others not–so, so I was interested to read an insider’s take into how the UK could fail so miserably.
Say you get a simple question like, how does the mortality rate from COVID-19 for our county (if you live in the United States and not Louisiana) compare to other counties in the state? Seems like a straightforward question right? Well not really. The first question is rate compared to what?
This post was spurred by the following tweet by Eric Topol and an associated response.
This post is completely inspired by @mjskay ’s very interesting analysis/ critique of a New York Times linear extrapolation of when the United States would reach the critical proportion for vaccination. The New York Times has made some amazing graphics during the pandemic, but their analyses have been pretty spotty. Between this linear extrapolation of vaccination rates and their SIRs for third and fourth waves, they really need to put some additional thought into the more math heavy type work.
Nassim Nicholas Taleb is a rather polarizing figure, but one point he makes over and over again is that it is better to trust someone who has “skin in the game.” If you have money on the table or stakes in the outcome, you typically sharpen your pencil and try to maximize your chance of winning (and edge or fold so to speak) when you don’t.
This is partially just for me to remember how to parameterise a Negative Binomial distribution. Typically, the Negative Binomial is used for the number of Bernoulli trials before the first success or number of successes is achieved (and thus a discrete distribution). For some probability of success, $p$, given $r$ failures and $k$ successes we can define the probability mass function as:
$$ {k + r - 1 \choose k} * (1-p)r*pk $$
Compartment models are commonly used in epidemiology to model epidemics. Compartmental model are composed of differential equations and captured some “knowns” regarding disease transmission. Because these models seek to simulate/ model the epidemic process directly, they are are somewhat more resistant to some biases (e.g. missing data). Strong-ish assumptions must be made regarding disease transmission and varying level of detail can be included in order to make the models closer to reality.
In this post I just wanted to play around using the ability to optimize functions in Stan. I know that there are other solvers available, but I just wanted to try this one to start (and I can’t find it now, but I think this was discussed in Regression and Other Stories).
This little post is based on a recent paper by Juul et al. (2020). For infectious disease modelling we are often running many scenarios through the models. Why? Because there are many parameters to estimate, but very few things that we actually observe (cases by day or incidence) so in some sense our models all suffer from identifiability issues. Additionally, many of the parameters that we do measure have some uncertainty around them. For this reason it is very common to run models with different parameters estimates or distributions in order to understand a range of possible values. A simple way to summarise these models is through point-wise quantiles through time. The genius of Juul’s paper is that this can underestimate many outcomes because it might pick up the beginning of one epidemic curve and miss the peak.
In this post I just wanted to play with julia and R together on the topic of agent based models. Agent based models have some particular advantages in that they capture the random effects of individuals in the model (and their shifting states). The downside of agent based models is of course that you have to program all of those transitions in your model. Regardless of that, they do show a much wider range of values and allow for very fined tune interactions and effects that you might miss with a deterministic model. I’m also using this as a way of exploring julia and the agents package which is built for this purpose.
One important concept that is discuss often is the role of sensitivity and specificity in testing. Here we are looking at the ability of a given diagnostic test to correctly identify true positives and correctly identify false positives. If you always forget which one is sensitivity and which one is specificity, no worries, I feel like everyone googles it.
ggplot2::
I just wanted to write up a quick exponential growth model for my county. I have been saddened that the local department of public health has been underestimating the power of exponential growth.
Like it or not, there are a lot of Windows shops out there. However, many super useful tools are Linux native and don’t really bridge into the Windows world (for good reason). That being said Windows and Microsoft (I think) are acknowledging this gap and have provided the Windows Linux Subsystem as a bridge between these two dominate platforms. This allows us little people to take advantage of some of the high powered tools available.
I’m not one for New Year’s resolutions, but this post is more about those things that I wish to accomplish in this coming year. Someone once told me that you should do a little of whatever you want to do in the coming year on New Year’s day (e.g. if you want to read more, read a bit; if you want to draw, sketch a little something). I would like to blog more, so this should start the year off right.
So I suppose this is a logical follow-up to the previous post. Now, instead of approval, we can look at impeachment.
This one is a quick one and based on some work that I have already done. Given the ongoing controversy about President Trump potentially using publically held funds to strong arm a foreign entity for personal and political gain, I figured it was time to do some state-space modeling on approval polls. This will be a quick one just because I want an answer.
This is a line that I heard and saw from a talk that James Savage at an NYC R Conference in which he discussed the importance of integrating over your loss function. I think that this is an infinitely important topic. Statisticians, myself included, often marvel over the the most parsimonious model with the highest explained variance or best predictive power. Additionally, when it comes to assessment and verifying the impact of an intervention, ensuring that one has accounted for as many of the confounding factors is important for uncovering the LATE or ATE (depending on the context).
Preview Image from shinyproxy.io
One of the neat things about ShinyProxy is that it allows you to package your Shiny applications into Docker containers and then serve them up via centralised “App Store” like front-end with all the goodies you might want (authentication, logging, etc). You get the bonus of building these containers in a container (so some dependency management) and scaling of containers with whatever backend you need.
With all of the media coverage, I have grown very nostalgic regarding the Apollo space program. It always amazes me to read the stories about the science and engineering that were sparked off by the space race.
What always amazes me is that years ago when memory was scarce and
computational power was expensive, tools were developed to parse and
manipulate data that fit these restrictions. Among these tools you find
things like AWK, SED, and the bourne shell. I have begun to
appreciate these tools for facilitating data work.
acme <- Node$
data <- acme$
data_raw <- acme$
libs <- acme$
munge <- acme$
src <- acme$
output <- acme$
reports <- acme$
readme <- acme$
makefile <- acme$
rproject <- acme$
A consistent workflow is very powerful for several key reasons:
One of the challenges in any kind of prediction problem is understand the impact of a) not identifying the target and b) the impact of falsely indentifying the target. To put it into context, if you are trying to use an algorithm to indentify those with ebola, whats the risk of missing someone (they could infect others with the disease) vs identifying someone who does not have the disease as having the disease (they get quarantined and have their life disrupted). Which is worse? That isn’t a statistical question, it is a context, and even an ethical question (ok, yes, you could also apply a loss function here and use that to find a global minimum value should it exist, but then again that is a choice).
I have always been interested in state space modeling. It is really interesting to see how this modeling strategy works in the realm of opinion polling. Luckily I stumbled across an example that James Savage put together for a workshop series on Econometrics in Stan. Additionally, while I was writing this blog post by happenstance Peter Ellis put out a similar state space Bayesian model for the most recent Australian elections. His forecasts were by far the most accurate out there and predicted the actual results. I wanted to borrow and extend from his work as well.
This is the original data collection routine from James Savage’s work.
# The polling data
realclearpolitics_all <-
# Scrape the data
polls <- realclearpolitics_all %>%
%>%
%>%
Develop a helper function.
# Function to convert string dates to actual dates
{
last_year <- >0
dates <-
dates <-
first_date <- %>% unlist
second_date <- %>% unlist
}
Continue cleaning.
# Convert dates to dates, impute MoE for missing polls with average of non-missing,
# and convert MoE to standard deviation (assuming MoE is the full 95% one sided interval length??)
polls <- polls %>%
%>%
%>%
%>%
%>%
# Stretch out to get missing values for days with no polls
polls3 <- %>%
%>%
%>%
I wanted to extend the data frame with blank values out until closer to the election. This is that step.
polls4 <- polls3 %>%
# One row for each day, one column for each poll on that day, -9 for missing values
Y_clinton <- polls4 %>% reshape2:: %>%
dplyr:: %>%
as.data.frame %>% as.matrix
Y_clinton <- -9
Y_trump <- polls4 %>% reshape2:: %>%
dplyr:: %>%
as.data.frame %>% as.matrix
Y_trump <- -9
# Do the same for margin of errors for those polls
sigma <- polls4 %>% reshape2::%>%
dplyr::%>%
as.data.frame %>% as.matrix
sigma <- -9
I have modified the model slightly to add the polling inflator that Peter Ellis uses in order to account for error outside of traditional polling error. There is a great deal of literature about this point in the Total Survey Error framework. Basically adding this inflator allows for additional uncertainty to be put into the model.
// From James Savage at https://github.com/khakieconomics/stanecon_short_course/blob/80263f84ebe95be3247e591515ea1ead84f26e3f/03-fun_time_series_models.Rmd
//and modification inspired by Peter Ellis at https://github.com/ellisp/ozfedelect/blob/master/model-2pp/model-2pp.R
// saved as models/state_space_polls.stan
data {
int polls; // number of polls
int T; // number of days
matrix[T, polls] Y; // polls
matrix[T, polls] sigma; // polls standard deviations
real inflator; // amount by which to multiply the standard error of polls
real initial_prior;
real random_walk_sd;
real mu_sigma;
}
parameters {
vector[T] mu; // the mean of the polls
real<lower = 0> tau; // the standard deviation of the random effects
matrix[T, polls] shrunken_polls;
}
model {
// prior on initial difference
mu[1] ~ normal(initial_prior, mu_sigma);
tau ~ student_t(4, 0, 5);
// state model
for(t in 2:T) {
mu[t] ~ normal(mu[t-1], random_walk_sd);
}
// measurement model
for(t in 1:T) {
for(p in 1:polls) {
if(Y[t, p] != -9) {
Y[t,p]~ normal(shrunken_polls[t, p], sigma[t,p] * inflator);
shrunken_polls[t, p] ~ normal(mu[t], tau);
} else {
shrunken_polls[t, p] ~ normal(0, 1);
}
}
}
}
state_space_model <-
clinton_data <-
trump_data <-
clinton_model <-
trump_model <-
# Pull the state vectors
mu_clinton <- %>%
as.data.frame
mu_trump <- %>%
as.data.frame
# Rename to get dates
<-
<-
# summarise uncertainty for each date
mu_ts_clinton <- mu_clinton %>% reshape2:: %>%
%>%
%>%
mu_ts_trump <- mu_trump %>% reshape2:: %>%
%>%
%>%
Which gives us the following:
actual_voteshare <-
%>%
+
+
+
+
+
+
+
+
+
+
+
+
+
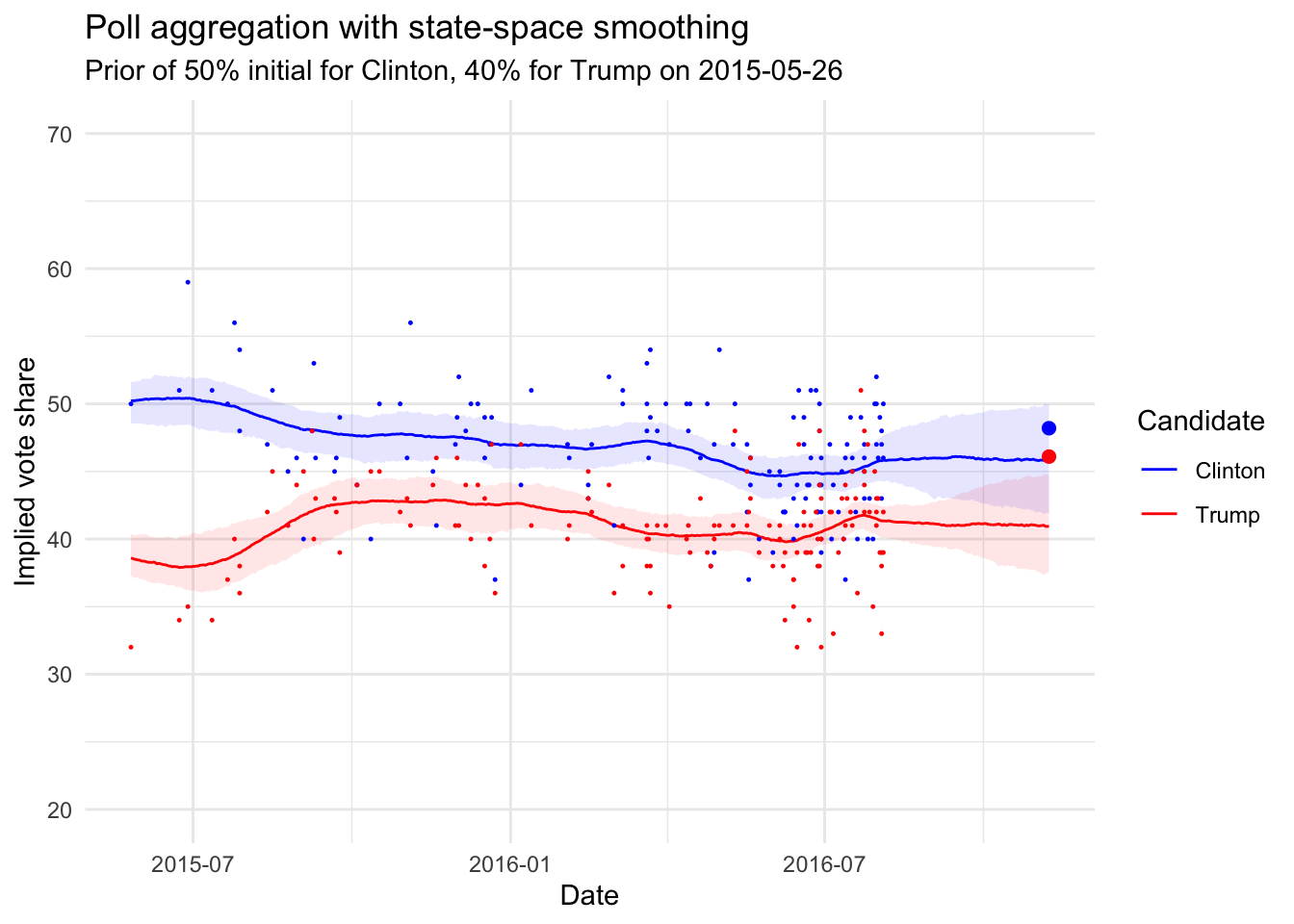
So the outcome was not totally out of the bounds of a good predictive model!
There was a recent bill introduced in the North Carolina General Assembly to reorganise the city counsel by two Republican state members of the General Assembly. The status quo is that there are a total of eight wards, each with a seat on the city counsel. The mayor votes only when there is a tie. As things are, the current city counsel is composed of four Black individuals and four white men, with a white man as mayor. The proposal from the General Assembly is to collapse several of the ward seats into five wards and then create three permanent at-large city counsel positions. Additionally, the mayor would have a vote on all matters, not just in ties.
One important concept to discuss is that of omited variable bias. This occurs when you have endogenous predictors that you do not adequately control for in your analysis.
I recently got a question about using MRP and I thought it would be worthwhile to share some of the additional explanation of using this approach with a simulated data set. Simulating your data and testing your method is a really good way to understand if your model is sensitive enough to detect differences. This kind of fake data simulation will allow you to see if your model fails, before using it production or in the field where the cost of failure is high.
I worked on something that started in R and then I wanted to speed it
up. MCMC is generally a slow process in base R because it can’t be
parallelised easily as each state depends on the previous state. Rcpp
is a wonderful avenue to speed things up.
This is a useful package to use latex notation in {ggplot2}. I saw
this on twitter and wish I had written down the originator for proper
citation but I forgot at the time.
This blogpost is a reproduction of this. Multi-level regression with post-stratification (MRP) is one of the more powerful predictive strategies for opinion polling and election forecasting. It combines the power of multi-level modeling which anticipate and predict group and population level effects which have good small N predictive properties with post-stratification which helps to temper the predictions to the demographics or other variables of interest. This method has been put out by Andrew Gelman et al and there is a good deal of literature on the subject.
Synthethic methods are a method of causal inference that seeks to combine traditional difference-in-difference types studies with time series cross sectional differences with factor analysis for uncontrolled/ unobserved measures. This method has been growing our of work initially from Abadie (Abadie, Diamond, and Hainmueller 2011a) and growing in importance/ research for state level policy analysis. It is interesting from the fact that it combines some elements of factor analysis to develop predictors and regression analysis to try to capture explained and unexplained variance.
The mission is to reproduce the figures in the following article:
https://cran.r-project.org/web/packages/hts/vignettes/hts.pdf
This post is basically a self exercise of what Andrew Gelman has already posted here. Fake data simulations are incredible tools to understand your study. It forces you to think about what is the size of the effect you wish to see, what kind of variance is in your model, if you can really detect it, will your design work, and the list goes on. Similar to any practice, when you have to think critically and put things to paper you tend to see the weaknesses of your arguments. It also helos you to anticipate issues. All of these things are priceless.
This post takes the example provided in Kosuke Imai’s Quantitative Social Science: An Introduction. It provides some exploration of network analysis through looking at the florentine dataset which counts the marraige relationships between several Florentine families in the 15th century. My historical side knows that our analysis should show that the [Medici Family] should appear at the center of all of the political intrigue. Let’s see if the analysis plays out.
I just wanted to explore a little more some of the topics covered in the fantastic Applied Econometrics with R. All of these examples come from their text in Chapter 3.
I enjoy reading Rob Hyndman’s blog. The other day he did some analysis of a short times series. More about that is available at his blog here. The neat thing that he shows is that you don’t need a tremendous amount of data to decompose seasonality. Using fourier transforms.
Look at this: https://robjhyndman.com/hyndsight/benchmark-combination/
I am inspired by the blog post completed by the team at stitchfix (see details here) regarding using item response theory for “latent size.” It is a neat approach. I need to say upfront that I am not a trained psychometrician, psychologist, etc. I understand the statistics, but there are nuances of which I know I am ignorant. However, I know that these methods are certainly worthwhile and worth pursuing.
Time series forecasting is interesting. I want to write more, but not right now. I’m just going to lay out a few functions for explanation later.
This will be a short post tonight. The topic is speeding up existing code. Typically the rule is make it work (e.g. do what you want it to do) before optimizing it. The trick then is that with some experience you can write your code so that you don’t box yourself into slow methods. That I won’t cover in this post.
Bayesian methods are where we need to go. I have pretty strong opinions on this as Bayes provides a way to attune for our prior understanding of the world, move away from null hypothesis testing and take advantage of prior work. Additionally, hierarchical modeling provides a way to collectively pool strength when you have a smaller number of data points. All in all it is a great way to do analysis.
gghighlight is a package that is on cran that allows one to highlight
certain features ones finds valuable. Right now I typically do this with
some custom color coding, then pass that into the ggplot2 arguments.
This might serve as a good way to more easily automate this task.
Additionally, this could be super handy during exploratory analysis
where this is much more iterative to find patterns.
So I am going to try to use this blog to capture programming tricks and examples of R coding, data visualisation and general musing that I find interesting. This is mainly for personal use and as a nice memory tool.