How About Impeachment?
Posted onSo I suppose this is a logical follow-up to the previous post. Now, instead of approval, we can look at impeachment.
The Data
Our friends at fivethirtyeight have not publically shared the polls that they have aggregated, so I will use my own aggregations.
dat <-
base_path <-
Multiple Polls on Multiple Days?
In order to build the data for Stan, it is necessary to make some wide data frame. Additionally, I need to calculate some standard errors. Just a reminder for those at home, the standard error for a binomial distribution is:
As I did last time, I’m also going to use some of the new pivot_*
functions from {tidyr}. They are great! These tools bring back some of
the functionality that was missing when {tidyr} emerged from {reshape2}.
It would probably be better to use the MOE as specified by the pollster
to get the true design effect, but just to crank this out, I am not
going to do that.
dat_range <-
formatted_data <- dat %>%
%>%
%>%
%>%
formatted_data <- -9
sigma <- formatted_data %>%
%>%
%>%
%>%
y <- formatted_data %>%
%>%
%>%
%>%
Our Model
This is the same model from this blog post and this one courtsey of James Savage and Peter Ellis.
// Base Syntax from James Savage at https://github.com/khakieconomics/stanecon_short_course/blob/80263f84ebe95be3247e591515ea1ead84f26e3f/03-fun_time_series_models.Rmd
//and modification inspired by Peter Ellis at https://github.com/ellisp/ozfedelect/blob/master/model-2pp/model-2pp.R
data {
int polls; // number of polls
int T; // number of days
matrix[T, polls] Y; // polls
matrix[T, polls] sigma; // polls standard deviations
real inflator; // amount by which to multiply the standard error of polls
real initial_prior;
real random_walk_sd;
real mu_sigma;
}
parameters {
vector[T] mu; // the mean of the polls
real<lower = 0> tau; // the standard deviation of the random effects
matrix[T, polls] shrunken_polls;
}
model {
// prior on initial difference
mu[1] ~ normal(initial_prior, mu_sigma);
tau ~ student_t(4, 0, 5);
// state model
for(t in 2:T) {
mu[t] ~ normal(mu[t-1], random_walk_sd);
}
// measurement model
for(t in 1:T) {
for(p in 1:polls) {
if(Y[t, p] != -9) {
Y[t,p]~ normal(shrunken_polls[t, p], sigma[t,p] * inflator);
shrunken_polls[t, p] ~ normal(mu[t], tau);
} else {
shrunken_polls[t, p] ~ normal(0, 1);
}
}
}
}
Prep the Data
Now we can put the data in the proper format for Stan. I’m also going to supply the 2016 voteshare as the initial prior. This is probably a favourable place to start.
approval_data <-
Run the Model
Now we can run the model. This might take a little while, but we have relatively sparse data and few instances per pollster, so it is what it is.
sstrump <-
trump_model <-
Did It Converge?
I’m just going to look quickly at some of the Rhat values. I see that some of my ESS are a little lower than I would like. This isn’t completely surprising given the sparsity of data (57 different polls).
$summary
Now Let’s see…
Now we can extract the model fit and see how it looks!
mu_trump <- %>%
as.data.frame
<-
mu_ts_trump <- mu_trump %>% reshape2:: %>%
%>%
%>%
More to Come
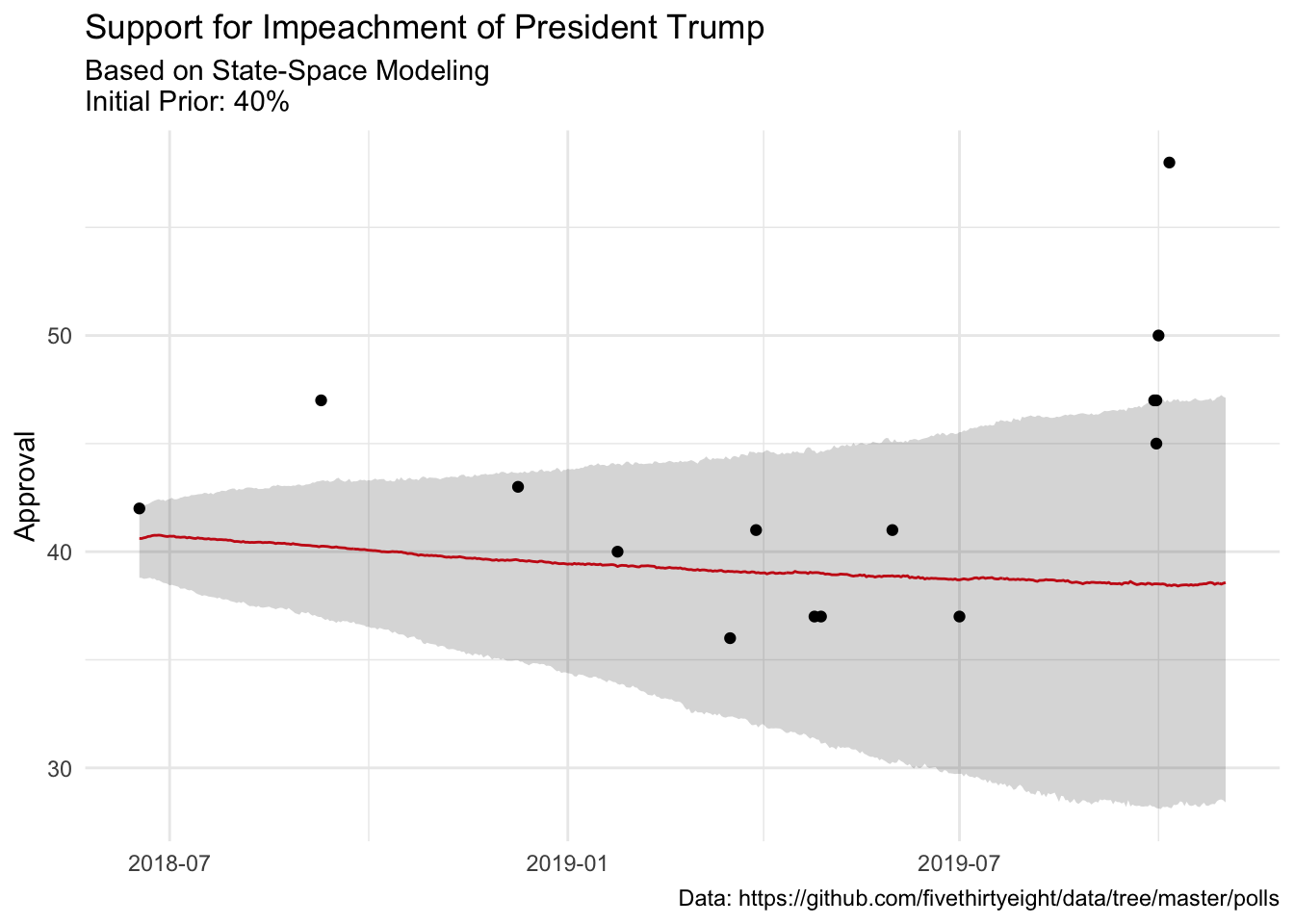
Our model has fairly wide credible intervals, which is to be expected, but the last few point estimates are clear…something is happening. And it looks like something that happened about a week or two has started to move the trend….
mu_ts_trump %>%
+
+
+
+
+
Citation
BibTex citation:
@online{dewitt2019
author = {Michael E. DeWitt},
title = {How About Impeachment?},
date = 2019-10-08,
url = {https://michaeldewittjr.com/articles/2019-10-08-how-about-impeachment},
langid = {en}
}
For attribution, please cite this work as:
Michael E. DeWitt. 2019. "How About Impeachment?." October 8, 2019. https://michaeldewittjr.com/articles/2019-10-08-how-about-impeachment